1. 測(cè)試數(shù)據(jù)準(zhǔn)備
第1步:創(chuàng)建數(shù)據(jù)庫、創(chuàng)建表
CREATE DATABASE dbtest3;
USE dbtest3;
#1.創(chuàng)建學(xué)生表和課程表
CREATE TABLE `student_info` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`student_id` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`course_id` INT NOT NULL ,
`class_id` INT(11) DEFAULT NULL,
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `course` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`course_id` INT NOT NULL ,
`course_name` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
第2步:創(chuàng)建模擬數(shù)據(jù)必需的存儲(chǔ)函數(shù)
說明: 創(chuàng)建函數(shù),假如報(bào)錯(cuò):
This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
由于開啟過慢查詢?nèi)罩綽in-log, 我們就必須為我們的 function 指定一個(gè)參數(shù)。
主從復(fù)制,主機(jī)會(huì)將寫操作記錄在bin-log日志中。從機(jī)讀取bin-log日志,執(zhí)行語句來同步數(shù)據(jù)。如果使 用函數(shù)來操作數(shù)據(jù),會(huì)導(dǎo)致從機(jī)和主鍵操作時(shí)間不一致。所以,默認(rèn)情況下,mysql不開啟創(chuàng)建函數(shù)設(shè) 置。
- 查看mysql是否允許創(chuàng)建函數(shù):
SHOW VARIABLES LIKE 'log_bin_trust_function_creators';
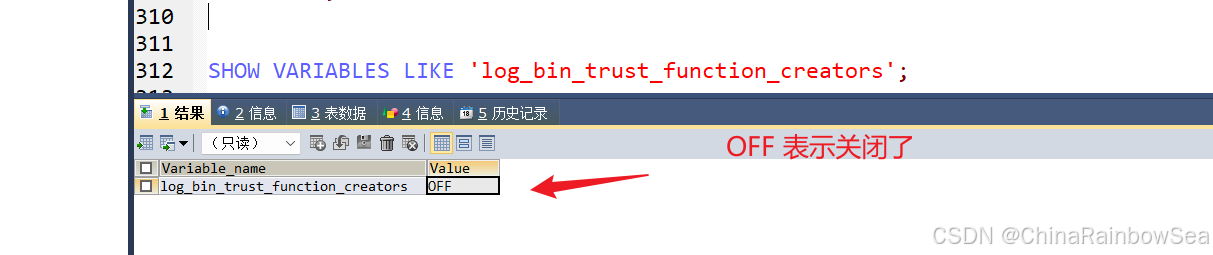
- 命令開啟:允許創(chuàng)建函數(shù)設(shè)置:
set global log_bin_trust_function_creators=1; # 不加global只是當(dāng)前窗口有效。

mysqld重啟,上述參數(shù)又會(huì)消失。永久方法:
- windows下:
my.ini[mysqld]加上:
log_bin_trust_function_creators=1 # 1 表示真-開啟,0 表示假-關(guān)閉
- linux下:
/etc/my.cnf 下my.cnf[mysqld]加上:
log_bin_trust_function_creators=1 # 1 表示真-開啟,0 表示假-關(guān)閉
#函數(shù)1:創(chuàng)建隨機(jī)產(chǎn)生字符串函數(shù)
DELIMITER //
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255) #該函數(shù)會(huì)返回一個(gè)字符串
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#函數(shù)2:創(chuàng)建隨機(jī)數(shù)函數(shù)
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND() * (to_num - from_num+1));
RETURN i;
END //
DELIMITER;
第3步:創(chuàng)建插入模擬數(shù)據(jù)的存儲(chǔ)過程
# 存儲(chǔ)過程1:創(chuàng)建插入課程表存儲(chǔ)過程
DELIMITER //
CREATE PROCEDURE insert_course( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #設(shè)置手動(dòng)提交事務(wù)
REPEAT #循環(huán)
SET i = i + 1; #賦值
INSERT INTO course (course_id, course_name ) VALUES (rand_num(10000,10100),rand_string(6));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事務(wù)
END //
DELIMITER;
# 存儲(chǔ)過程2:創(chuàng)建插入學(xué)生信息表存儲(chǔ)過程
DELIMITER //
CREATE PROCEDURE insert_stu( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #設(shè)置手動(dòng)提交事務(wù)
REPEAT # 循環(huán)
SET i = i + 1; # 賦值
INSERT INTO student_info (course_id,class_id,student_id,`NAME`) VALUES
(rand_num(10000,10100),rand_num(10000,10200),rand_num(1,200000),rand_string(6));
UNTIL i = max_num
END REPEAT;
COMMIT; # 提交事務(wù)
END //
DELIMITER ;
第4步:調(diào)用存儲(chǔ)過程
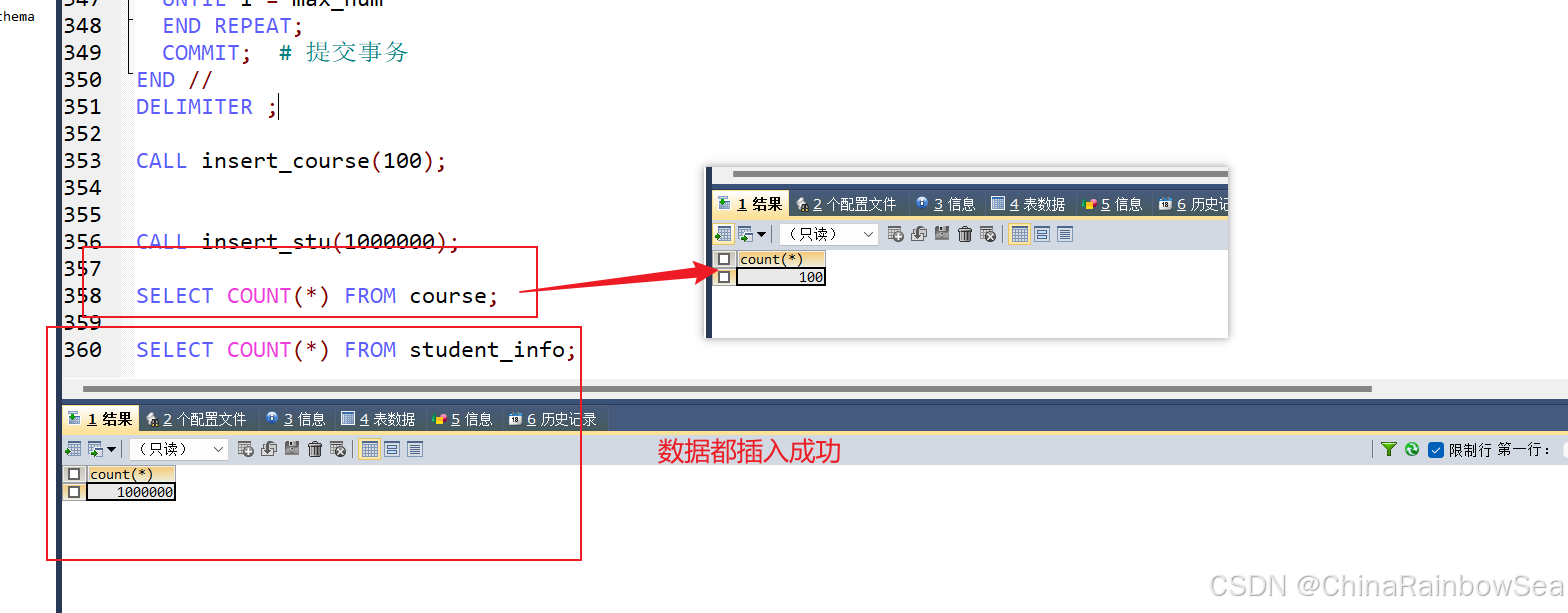
CALL insert_course(100);
CALL insert_stu(1000000);
第5步:查看是否含有這么多數(shù)據(jù),數(shù)據(jù)是否插入成功
SELECT COUNT(*) FROM course;
SELECT COUNT(*) FROM student_info;
2. 哪些情況適合創(chuàng)建索引
2.1 字段的數(shù)值有唯一性的限制
索引本身可以起到約束的作用,比如:唯一索引,主鍵索引都是可以起到唯一性約束的,因此在我們的數(shù)據(jù)表中,如果某個(gè)字段是唯一性的 ,就可以直接創(chuàng)建唯一性索引 ,或者主鍵索引。這樣可以更快速地通過該索引來確定某條記錄。
例如:學(xué)生表中學(xué)號(hào) 是具有唯一性的字段,為該字段建立唯一性索引可以很快確定某個(gè)學(xué)生的信息,如果使用姓名 的話,可能存在同名現(xiàn)象,從而減低查詢速度。
業(yè)務(wù)上具有唯一特性的字段,即使是組合字段,也必須建成唯一索引。(來源:Alibaba)
說明:不要以為唯一索引影響了 insert 速度,這個(gè)速度損耗可以忽略,但提高查找速度是明顯s的。
2.2 頻繁作為 WHERE 查詢條件的字段
某個(gè)字段在SELECT語句的 WHERE 條件中經(jīng)常被使用到,那么就需要給這個(gè)字段創(chuàng)建索引了。尤其是在 數(shù)據(jù)量大的情況下,創(chuàng)建普通索引就可以大幅提升數(shù)據(jù)查詢的效率。
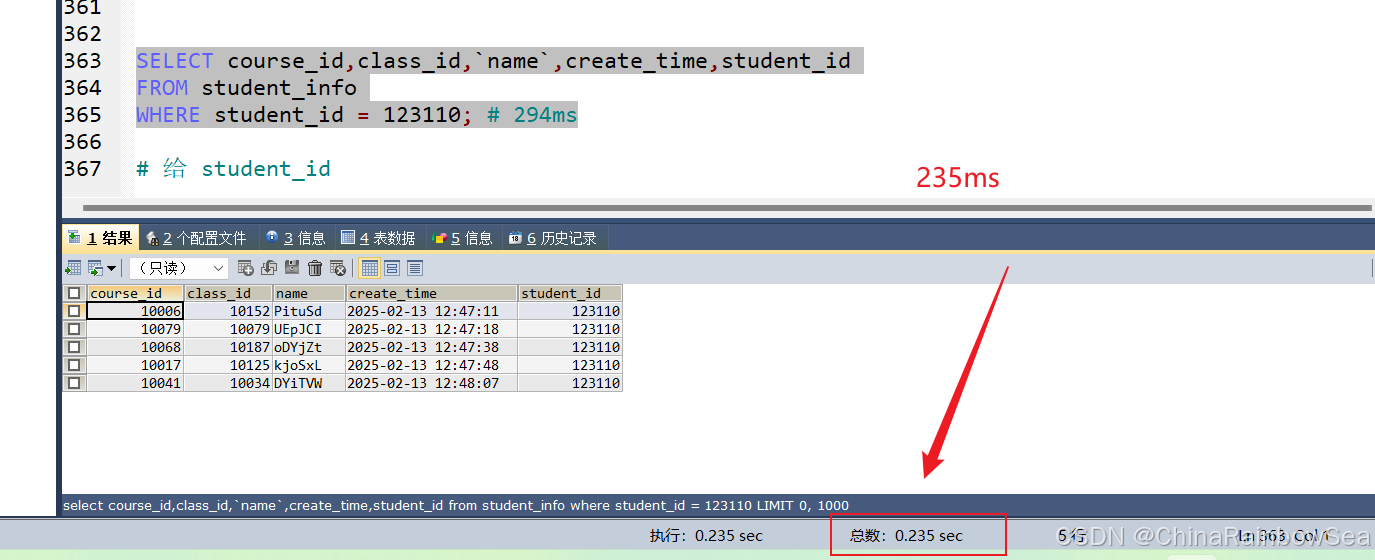
比如 student_info數(shù)據(jù)表(含100萬條數(shù)據(jù)),假設(shè)我們想要查詢 student_id=123110 的用戶信息。
沒有給 student_id 字段添加索引,執(zhí)行的速度是:
SELECT course_id,class_id,`name`,create_time,student_id
FROM student_info
WHERE student_id = 123110;
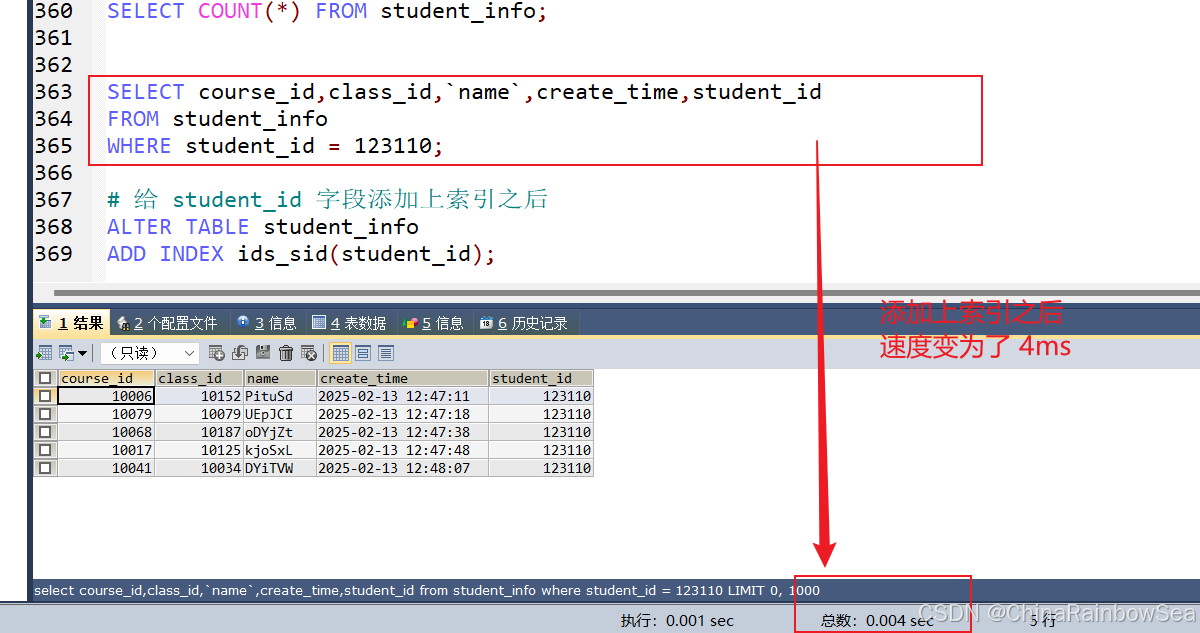
# 給 student_id 字段添加上索引之后
ALTER TABLE student_info
ADD INDEX ids_sid(student_id);
2.3 經(jīng)常 GROUP BY 和 ORDER BY 的列
索引就是讓數(shù)據(jù)按照某種順序進(jìn)行存儲(chǔ)或檢索,因此當(dāng)我們使用 GROUP BY 對(duì)數(shù)據(jù)進(jìn)行分組查詢,或者 使用 ORDER BY 對(duì)數(shù)據(jù)進(jìn)行排序的時(shí)候,就需要對(duì)分組或者排序的字段進(jìn)行索引 。如果待排序的列有多 個(gè),那么可以在這些列上建立 組合索引 。
# 經(jīng)常 GROUP BY 和 ORDER BY 的列
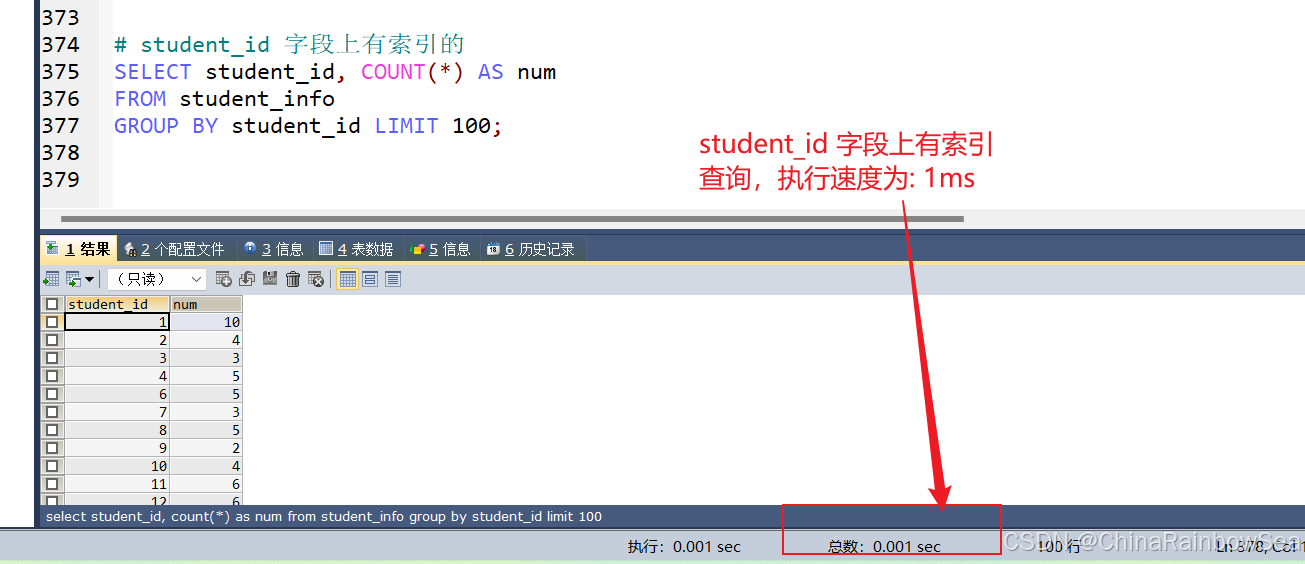
# student_id 字段上有索引的
SELECT student_id, COUNT(*) AS num
FROM student_info
GROUP BY student_id LIMIT 100;
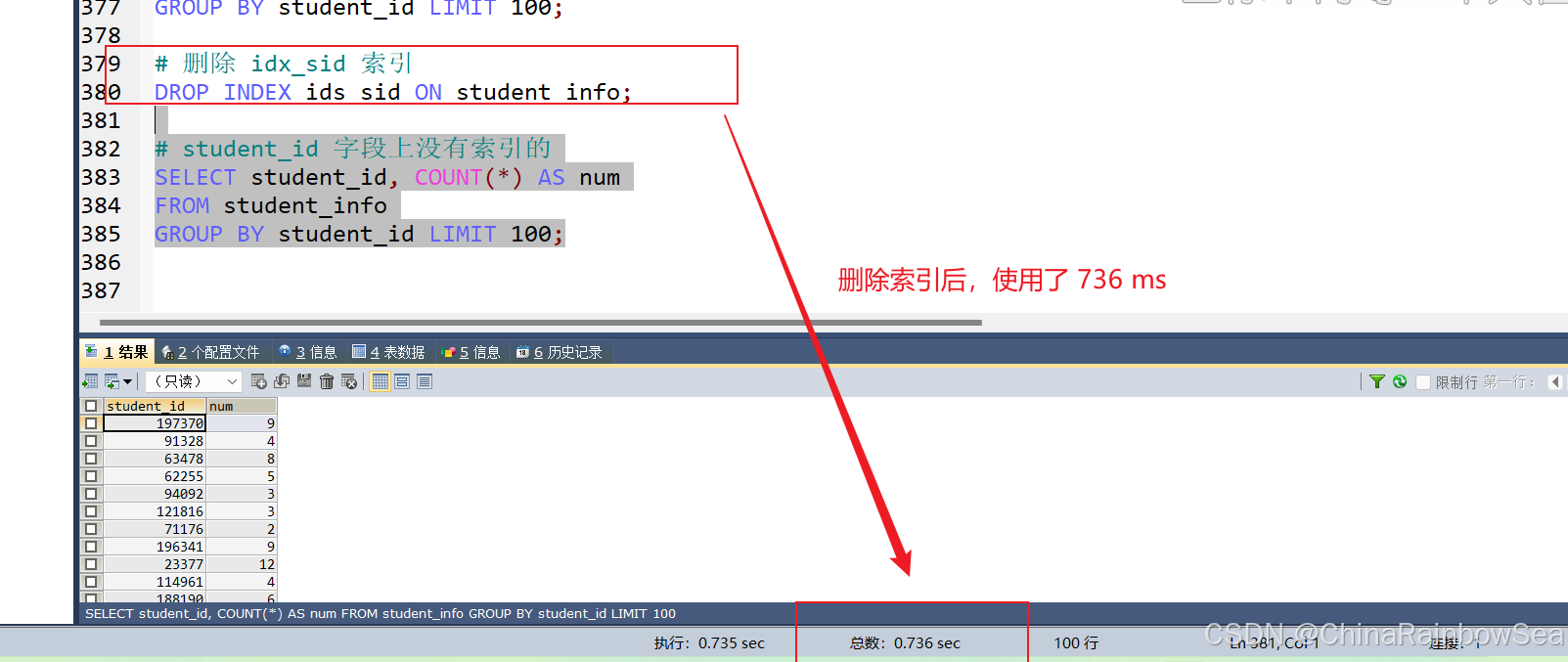
# 刪除 idx_sid 索引
DROP INDEX ids_sid ON student_info;
# student_id 字段上沒有索引的
SELECT student_id, COUNT(*) AS num
FROM student_info
GROUP BY student_id LIMIT 100;
如果同時(shí)有 GROUP By 和 ORDER BY 的情況:比如我們按照 student_id 進(jìn)行分組,同時(shí)按照創(chuàng)建時(shí)間降序的方式進(jìn)行排序,這時(shí)我們就需要同時(shí)進(jìn)行 GROUP BY 和 ORDER BY,那么是不是需要單獨(dú)創(chuàng)建 student_id 的索引和 create_time 的索引呢?
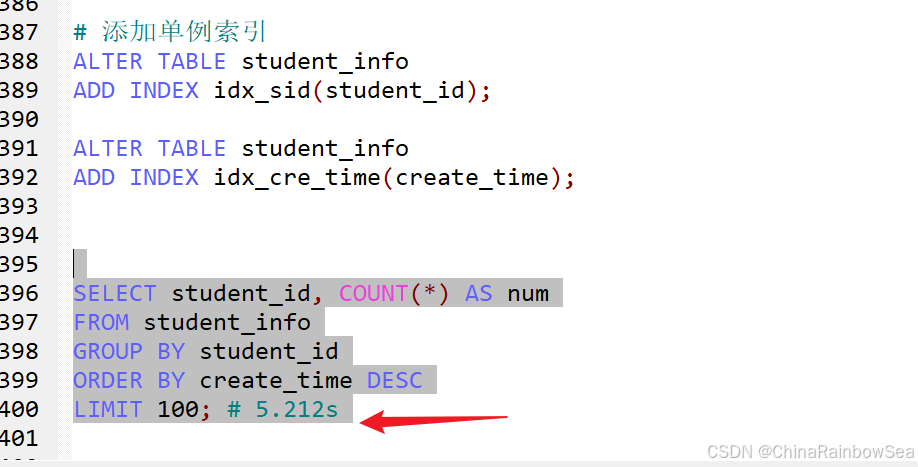
當(dāng)我們對(duì) student_id 和 create_time 分別創(chuàng)建索引,執(zhí)行下面的SQL查詢
# 添加單例索引
ALTER TABLE student_info
ADD INDEX idx_sid(student_id);
ALTER TABLE student_info
ADD INDEX idx_cre_time(create_time);
SELECT student_id, COUNT(*) AS num
FROM student_info
GROUP BY student_id
ORDER BY create_time DESC
LIMIT 100; # 5.212s
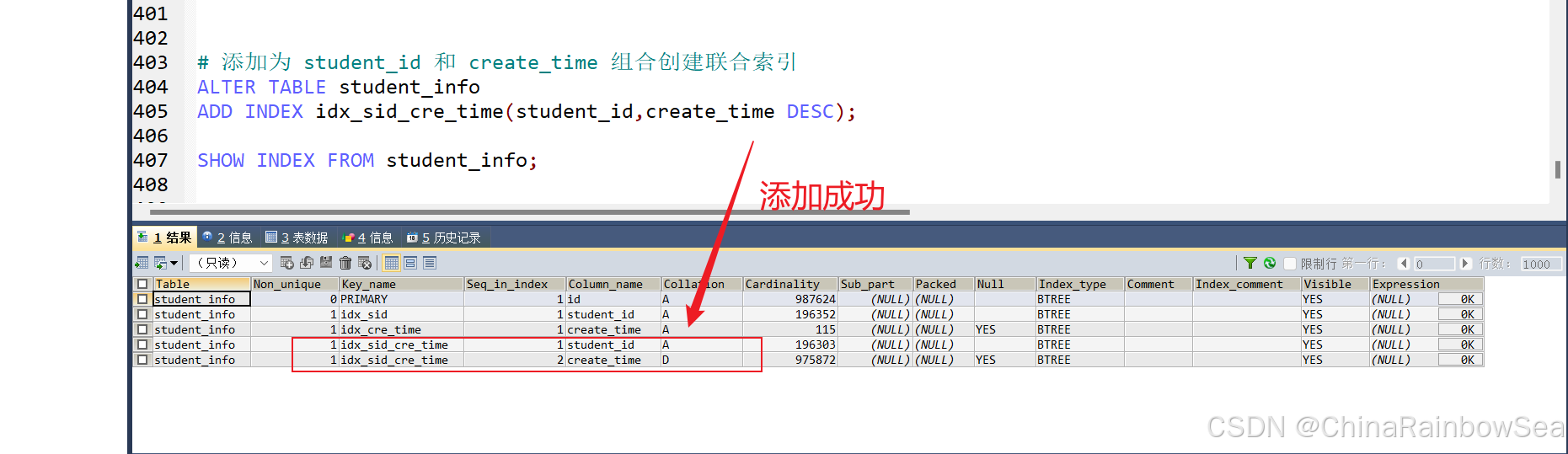
當(dāng)我們添加對(duì) student_id 和 create_time 組合創(chuàng)建聯(lián)合索引,執(zhí)行下面的SQL查詢
# 添加為 student_id 和 create_time 組合創(chuàng)建聯(lián)合索引
ALTER TABLE student_info
ADD INDEX idx_sid_cre_time(student_id,create_time DESC);
SHOW INDEX FROM student_info;
再次執(zhí)行該SQL語句:

2.4 UPDATE、DELETE 的 中的WHERE 條件列添加索引
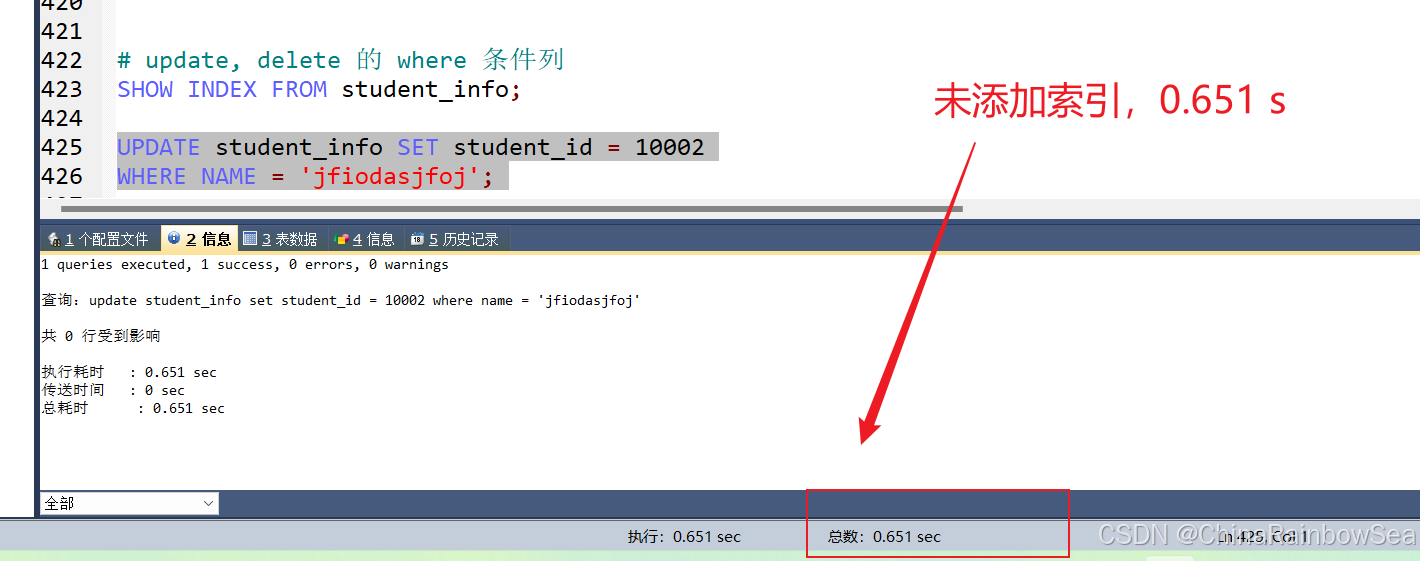
對(duì)數(shù)據(jù)按照某個(gè)條件進(jìn)行查詢后再進(jìn)行 UPDATE 或 DELETE 的操作,如果對(duì) WHERE 字段創(chuàng)建了索引,就 能大幅提升效率。原理是因?yàn)槲覀冃枰雀鶕?jù) WHERE 條件列檢索出來這條記錄,然后再對(duì)它進(jìn)行更新或 刪除。 如果進(jìn)行更新的時(shí)候,更新的字段是非索引字段,提升的效率會(huì)更明顯,這是因?yàn)榉撬饕侄胃?新不需要對(duì)索引進(jìn)行維護(hù)。
# update, delete 的 where 條件列添加索引
SHOW INDEX FROM student_info;
UPDATE student_info SET student_id = 10002
WHERE NAME = 'jfiodasjfoj';
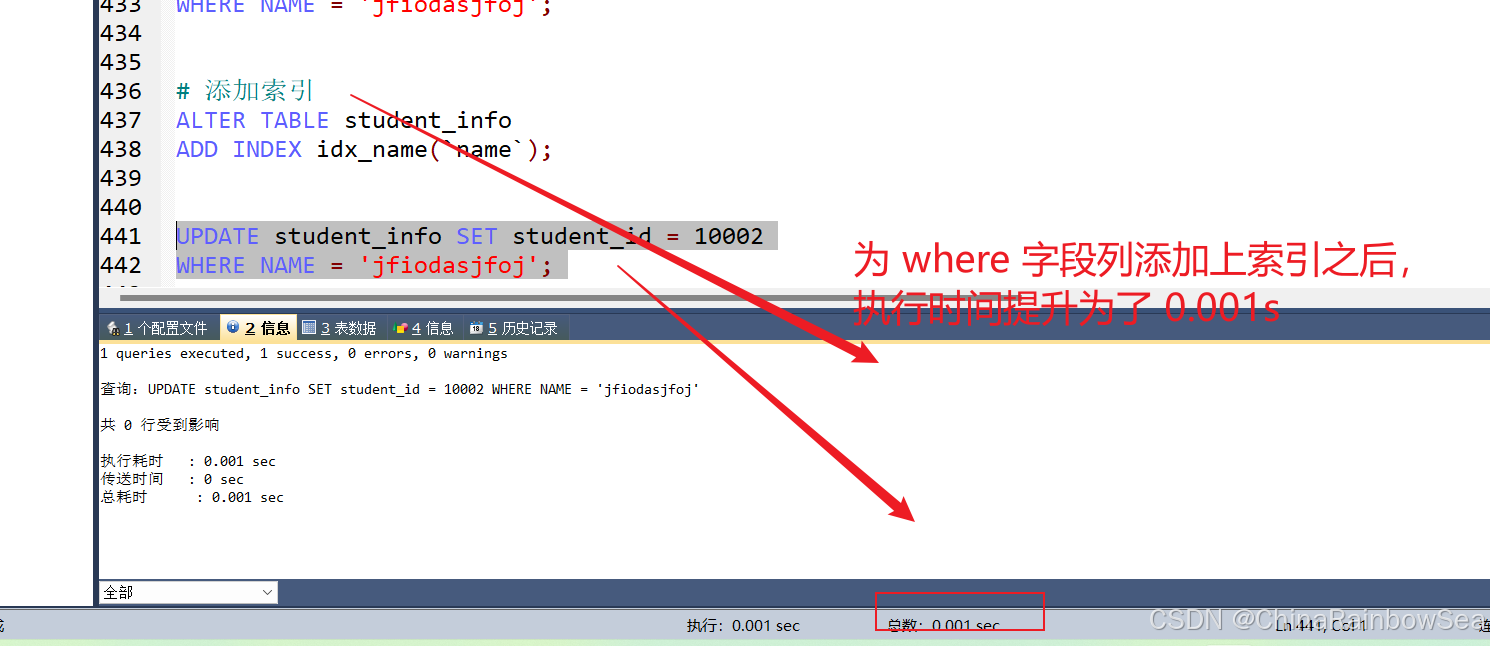
為 name 添加上索引
# 添加索引
ALTER TABLE student_info
ADD INDEX idx_name(`name`);
UPDATE student_info SET student_id = 10002
WHERE NAME = 'jfiodasjfoj';
2.5 對(duì)于經(jīng)常 DISTINCT 字段需要?jiǎng)?chuàng)建索引
有時(shí)候我們需要對(duì)某個(gè)字段進(jìn)行去重,使用 DISTINCT,那么對(duì)這個(gè)字段創(chuàng)建索引,也會(huì)提升查詢效率。 比如,我們想要查詢課程表中不同的 student_id 都有哪些,如果我們沒有對(duì) student_id 創(chuàng)建索引,執(zhí)行 SQL 語句:
SELECT DISTINCT(student_id) FROM `student_info`;
運(yùn)行結(jié)果(600637 條記錄,運(yùn)行時(shí)間 0.683s ):
如果我們對(duì) student_id 創(chuàng)建索引,再執(zhí)行 SQL 語句:
SELECT DISTINCT(student_id) FROM `student_info`;
運(yùn)行結(jié)果(600637 條記錄,運(yùn)行時(shí)間 0.010s ):
你能看到 SQL 查詢效率有了提升,同時(shí)顯示出來的 student_id 還是按照 遞增的順序 進(jìn)行展示的。這是因 為索引會(huì)對(duì)數(shù)據(jù)按照某種順序進(jìn)行排序,所以在去重的時(shí)候也會(huì)快很多。
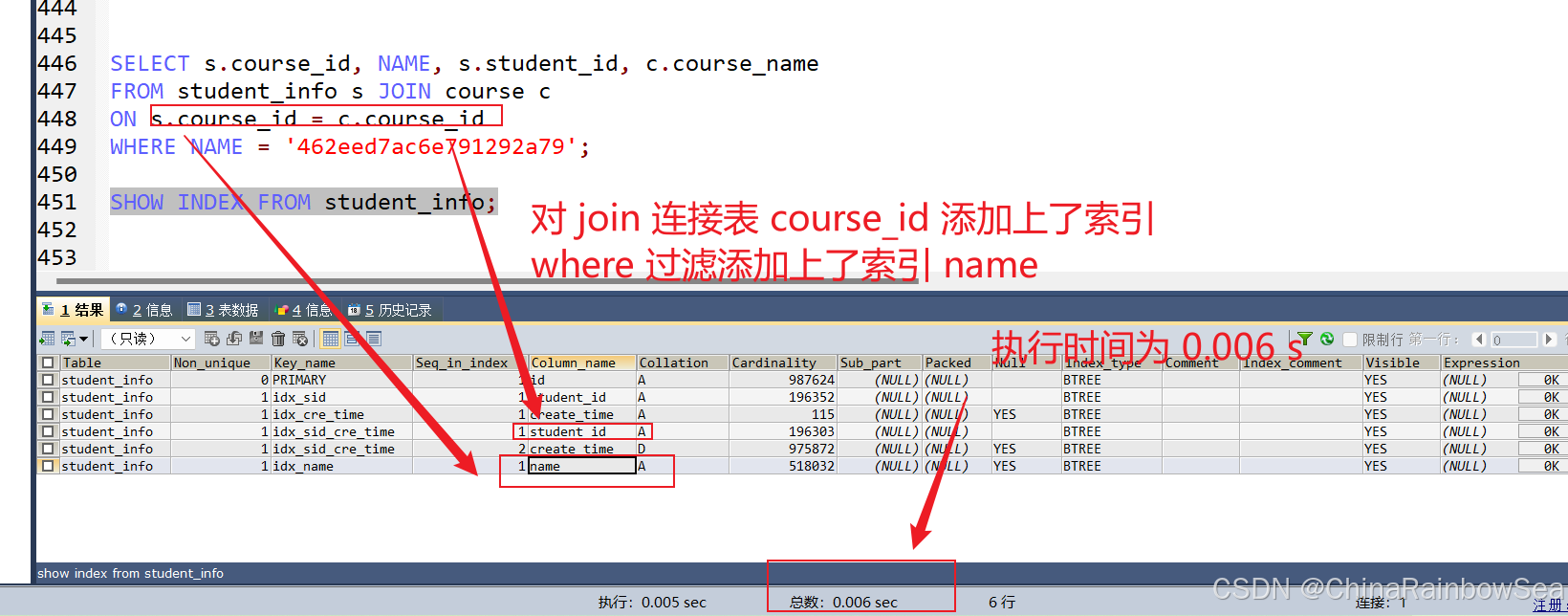
2.6 多表 JOIN 連接操作時(shí),創(chuàng)建索引注意事項(xiàng)
- 首先,
連接表的數(shù)量盡量不要超過 3 張 ,因?yàn)槊吭黾右粡埍砭拖喈?dāng)于增加了一次嵌套的循環(huán),數(shù)量級(jí)增 長(zhǎng)會(huì)非常快,嚴(yán)重影響查詢的效率。 - 其次,
對(duì) WHERE 條件創(chuàng)建索引 ,因?yàn)?WHERE 才是對(duì)數(shù)據(jù)條件的過濾。如果在數(shù)據(jù)量非常大的情況下, 沒有 WHERE 條件過濾是非常可怕的。 - 最后,
對(duì)用于連接的字段創(chuàng)建索引 ,并且該字段在多張表中的 類型必須一致 。比如 course_id 在 student_info 表和 course 表中都為 int(11) 類型,而不能一個(gè)為 int 另一個(gè)為 varchar 類型。
舉個(gè)例子,如果我們只對(duì) student_id 和 name 創(chuàng)建索引,執(zhí)行 SQL 語句:
SELECT s.course_id, NAME, s.student_id, c.course_name
FROM student_info s JOIN course c
ON s.course_id = c.course_id
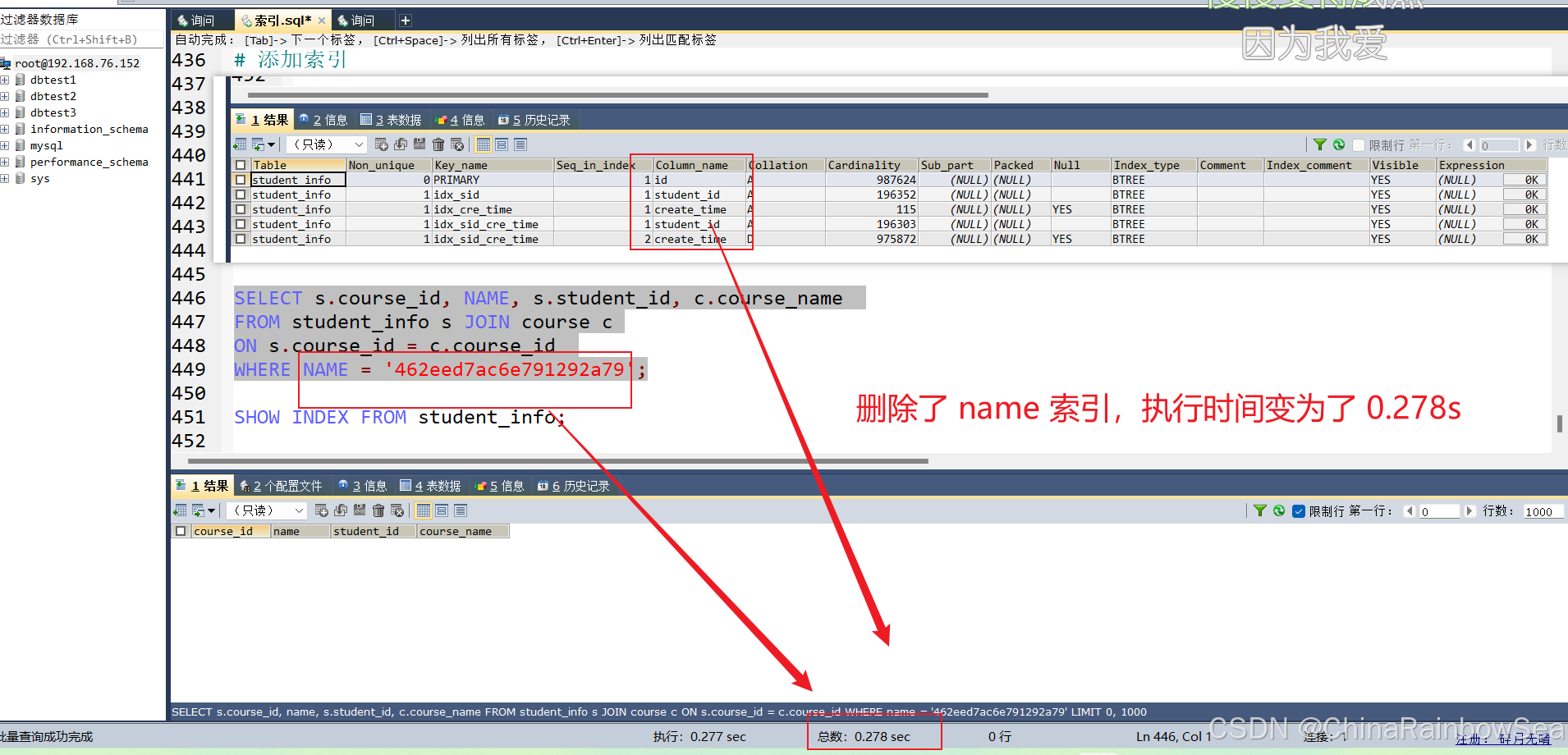
WHERE NAME = '462eed7ac6e791292a79';
DROP INDEX idx_name ON student_info;
SELECT s.course_id, NAME, s.student_id, c.course_name
FROM student_info s JOIN course c
ON s.course_id = c.course_id
WHERE NAME = '462eed7ac6e791292a79';
2.7 使用列的類型小的創(chuàng)建索引
使用列小的類型,創(chuàng)建的索引占用的磁盤空間就比較小一些,因?yàn)镸ySQL8 是將索引和數(shù)據(jù)都是存放再一起的。
我們這里所說的類型大小 指的就是該類型表示的數(shù)據(jù)范圍的大小。
我們?cè)诙x表結(jié)構(gòu)的時(shí)候要顯式的指定列的類型,以整數(shù)類型為例,有TINYINT,MEDIUMINT,INT,BIGINT 等,它們占用的存儲(chǔ)空間依次遞增,能表示的整數(shù)范圍當(dāng)然也是依次遞增,如果我們想要對(duì)某個(gè)整數(shù)列建立索引的話,在表示的整數(shù)范圍允許的情況下,盡量讓索引列使用較小的類型,比如我們能使用 INT 就不要使用 BIGINT ,能使用 MEDIUMINT 就不要使用 INT 。
2.8 使用字符串前綴創(chuàng)建索引
創(chuàng)建一張商戶表,因?yàn)榈刂纷侄伪容^長(zhǎng),在地址字段上建立前綴索引
- 創(chuàng)建一張商戶表,因?yàn)榈刂纷侄伪容^長(zhǎng),在地址字段上建立前綴索引
create table shop(address varchar(120) not null);
alter table shop add index(address(12));
問題是,截取多少呢?截取得多了,達(dá)不到節(jié)省索引存儲(chǔ)空間的目的;截取得少了,重復(fù)內(nèi)容太多,字 段的散列度(選擇性)會(huì)降低。 怎么計(jì)算不同的長(zhǎng)度的選擇性呢?
先看一下字段在全部數(shù)據(jù)中的選擇度:
select count(distinct address) / count(*) from shop;
通過不同長(zhǎng)度去計(jì)算,與全表的選擇性對(duì)比:
公式:
count(distinct left(列名, 索引長(zhǎng)度))/count(*);
例如:
select count(distinct left(address,10)) / count(*) as sub10,
count(distinct left(address,15)) / count(*) as sub11,
count(distinct left(address,20)) / count(*) as sub12,
count(distinct left(address,25)) / count(*) as sub13
from shop;
引申另一個(gè)問題:索引列前綴對(duì)排序的影響
拓展:Alibaba《Java開發(fā)手冊(cè)》
- 【 強(qiáng)制 】在 varchar 字段上建立索引時(shí),必須指定索引長(zhǎng)度,沒必要對(duì)全字段建立索引,根據(jù)實(shí)際文本 區(qū)分度決定索引長(zhǎng)度。
- 說明:索引的長(zhǎng)度與區(qū)分度是一對(duì)矛盾體,一般對(duì)字符串類型數(shù)據(jù),長(zhǎng)度為 20 的索引,區(qū)分度會(huì)
高達(dá) 90% 以上 ,可以使用 count(distinct left(列名, 索引長(zhǎng)度))/count(*)的區(qū)分度來確定。
2.9 區(qū)分度高(散列性高)的列適合作為索引
列的基數(shù) 指的是某一列中不重復(fù)數(shù)據(jù)的個(gè)數(shù),比方說某個(gè)列包含值2,5,8,2,5,8,2,5,8 ,雖然有9 條記錄,但該列的基數(shù)卻是3。也就是說,在記錄行數(shù)一定的情況下,列的基數(shù)越大,該列中的值越分散;列的基數(shù)越小,該列中值越集中 。這個(gè)列的基數(shù)指標(biāo)非常重要,直接影響我們是否能夠有效的利用索引。最好為列的基數(shù)大的列建立索引,為基數(shù)太小的列建立索引效果可能不好。
可以使用公式:select count(distinct a) / count(*) from t1 計(jì)算區(qū)分度,越接近 1 越好,一般超過 33% 就算是比較高效的索引了。
拓展:聯(lián)合索引把區(qū)分度高(散列性高)的列放在前面。
2.10 使用最頻繁的列放到聯(lián)合索引的左側(cè)——索引最左側(cè)匹配
索引最左側(cè)匹配的原則,索引會(huì)優(yōu)先判斷最左側(cè)的字段是否,建立的索引,建立了索引就會(huì)走索引,如果左側(cè)的字段沒有走索引,就算后面的字段有索引,也不會(huì)走索引的。
3. 哪些情況不適合創(chuàng)建索引
3.1 在 where 篩選條件當(dāng)中使用不到的字段,不要設(shè)置索引
你都不對(duì)該字段,進(jìn)行篩選過濾,那么索引你沒有意義,因?yàn)槟闼饕彩菚?huì)增加磁盤空間大小的。
3.2 數(shù)據(jù)量小的表最好不要使用索引
舉例:創(chuàng)建表1:
CREATE TABLE t_without_index(
a INT PRIMARY KEY AUTO_INCREMENT, b INT
);
提供存儲(chǔ)過程1:
#創(chuàng)建存儲(chǔ)過程
DELIMITER //
CREATE PROCEDURE t_wout_insert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 900
DO
INSERT INTO t_without_index(b) SELECT RAND()*10000;
SET i = i + 1;
END WHILE;
COMMIT;
END //
DELIMITER ;
#調(diào)用
CALL t_wout_insert();
創(chuàng)建表2:
CREATE TABLE t_with_index(
a INT PRIMARY KEY AUTO_INCREMENT, b INT,
INDEX idx_b(b) );
創(chuàng)建存儲(chǔ)過程2:
#創(chuàng)建存儲(chǔ)過程
DELIMITER //
CREATE PROCEDURE t_with_insert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 900
DO
INSERT INTO t_with_index(b) SELECT RAND()*10000;
SET i = i + 1;
END WHILE;
COMMIT;
END //
DELIMITER ;
#調(diào)用
CALL t_with_insert();
查詢對(duì)比:
mysql> select * from t_without_index where b = 9879;
+
|a |b |
+
| 1242 | 9879 |
+
1 row in set (0.00 sec)
mysql> select * from t_with_index where b = 9879;
+
|a |b |
+
| 112 | 9879 |
+
1 row in set (0.00 sec)
你能看到運(yùn)行結(jié)果相同,但是在數(shù)據(jù)量不大的情況下,索引就發(fā)揮不出作用了。
結(jié)論:在數(shù)據(jù)表中的數(shù)據(jù)行數(shù)比較少的情況下,比如不到 1000 行,是不需要?jiǎng)?chuàng)建索引的。
3.3 有大量重復(fù)數(shù)據(jù)的列上不要建立索引
舉例1:要在 100 萬行數(shù)據(jù)中查找其中的 50 萬行(比如性別為男的數(shù)據(jù)),一旦創(chuàng)建了索引,你需要先 訪問 50 萬次索引,然后再訪問 50 萬次數(shù)據(jù)表,這樣加起來的開銷比不使用索引可能還要大。
舉例2:假設(shè)有一個(gè)學(xué)生表,學(xué)生總數(shù)為 100 萬人,男性只有 10 個(gè)人,也就是占總?cè)丝诘?10 萬分之 1。 學(xué)生表 student_gender 結(jié)構(gòu)如下。其中數(shù)據(jù)表中的 student_gender 字段取值為 0 或 1,0 代表女性,1 代 表男性。
CREATE TABLE student_gender(
student_id INT(11) NOT NULL,
student_name VARCHAR(50) NOT NULL,
student_gender TINYINT(1) NOT NULL,
PRIMARY KEY(student_id)
)ENGINE = INNODB;
如果我們要篩選出這個(gè)學(xué)生表中的男性,可以使用:
SELECT * FROM student_gender WHERE student_gender = 1
運(yùn)行結(jié)果(10 條數(shù)據(jù),運(yùn)行時(shí)間 0.696s ):
結(jié)論:當(dāng)數(shù)據(jù)重復(fù)度大,比如 高于 10% 的時(shí)候,也不需要對(duì)這個(gè)字段使用索引。
3.4 避免對(duì)經(jīng)常更新的表創(chuàng)建過多的索引
因?yàn)槟悴粩喔卤淼耐瑫r(shí),索引也是在同步更新的,索引更新是會(huì)消耗大量的時(shí)間。
3.5 不建議用無序的值作為索引
例如身份證、UUID(在索引比較時(shí)需要轉(zhuǎn)為ASCII,并且插入時(shí)可能造成頁分裂)、MD5、HASH、無序長(zhǎng)字 符串等。
3.6 刪除不再使用或者很少使用的索引
3.7 不要定義冗余或重復(fù)的索引
冗余索引
舉例:建表語句如下
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number),
KEY idx_name (name(10))
);
我們知道,通過 idx_name_birthday_phone_number 索引就可以對(duì) name列進(jìn)行快速搜索,再創(chuàng)建一 個(gè)專門針對(duì) name列的索引就算是一個(gè) 冗余索引 ,維護(hù)這個(gè)索引只會(huì)增加維護(hù)的成本,并不會(huì)對(duì)搜索有 什么好處.。
重復(fù)索引:
另一種情況,我們可能會(huì)對(duì)某個(gè)列 重復(fù)建立索引 ,比方說這樣:
CREATE TABLE repeat_index_demo (
col1 INT PRIMARY KEY,
col2 INT,
UNIQUE uk_idx_c1 (col1),
INDEX idx_c1 (col1)
);
我們看到,col1 既是主鍵、又給它定義為一個(gè)唯一索引,還給它定義了一個(gè)普通索引,可是主鍵本身就 會(huì)生成聚簇索引,所以定義的唯一索引和普通索引是重復(fù)的,這種情況要避免。
?轉(zhuǎn)自https://www.cnblogs.com/TheMagicalRainbowSea/p/18731859
該文章在 2025/3/7 9:50:55 編輯過
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

